使用参考的自动化单细胞细胞类型注释#
截至2025年,用于自动细胞类型注释的算法已大幅增加。Omicverse致力于减少不同算法之间的差异,因此我们将自动注释方法分为两类:带有单细胞参考和没有单细胞参考。每个类别都有其自身的优缺点。在本教程中,我们仅介绍使用方法,不会比较不同的算法。
本章重点关注带有单细胞参考方法,这涉及使用现有标记的单细胞数据集作为参考。
# 导入库
import scanpy as sc
import omicverse as ov
ov.plot_set(font_path='Arial')
🔬 Starting plot initialization...
Using already downloaded Arial font from: /tmp/omicverse_arial.ttf
Registered as: Arial
🧬 Detecting GPU devices…
✅ NVIDIA CUDA GPUs detected: 1
• [CUDA 0] NVIDIA H100 80GB HBM3
Memory: 79.1 GB | Compute: 9.0
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
🔖 Version: 1.7.8rc2 📚 Tutorials: https://omicverse.readthedocs.io/
✅ plot_set complete.
数据预处理#
加载数据集#
为了快速演示我们在使用参考的细胞类型注释方面的能力,我们使用经典的pbmc3k数据集作为查询数据和更大的PBMC参考数据集。
adata=ov.datasets.pbmc3k()adata
Loading PBMC 3k dataset (raw)
🔍 Downloading data to ./data/pbmc3k_raw.h5ad
⚠️ File ./data/pbmc3k_raw.h5ad already exists
Loading data from ./data/pbmc3k_raw.h5ad
✅ Successfully loaded: 2700 cells × 32738 genes
AnnData object with n_obs × n_vars = 2700 × 32738
var: 'gene_ids'
加载参考数据集#
我们从Zenodo(一个开源数据存储库)下载已注释的PBMC参考数据集。
懒惰预处理#
为了与参考数据兼容,我们对查询数据应用了相同的预处理程序。
obj=ov.single.Annotation(adata)res=obj.query_reference( source='cellxgene', data_desc='PBMC for human', llm_model='gpt-5-mini', llm_api_key='sk-*', llm_provider='openai', llm_base_url='https://api.openai.com/v1',)
正在访问 API: https://api.cellxgene.cziscience.com/curation/v1/collections
✓ API 访问成功 (状态码: 200)
CellxGene description dataframe saved to self.cellxgene_desc_df
✓ LLM-selected CellxGene collections:
- dde06e0f-ab3b-46be-96a2-a8082383c4a1: Single-cell eQTL mapping identifies cell type specific genetic control of autoimmune disease (https://cellxgene.cziscience.com/collections/dde06e0f-ab3b-46be-96a2-a8082383c4a1)
- ced320a1-29f3-47c1-a735-513c7084d508: Asian Immune Diversity Atlas (AIDA) (https://cellxgene.cziscience.com/collections/ced320a1-29f3-47c1-a735-513c7084d508)
- e9360edf-b0b7-4e01-bce8-e596814f13e7: Multi-omic profiling reveals age-related immune dynamics in healthy adults (https://cellxgene.cziscience.com/collections/e9360edf-b0b7-4e01-bce8-e596814f13e7)
- 4a9fd4d7-d870-4265-89a5-ad51ab811d89: ScaleBio Single Cell RNA Sequencing of Human PBMCs (https://cellxgene.cziscience.com/collections/4a9fd4d7-d870-4265-89a5-ad51ab811d89)
- 436154da-bcf1-4130-9c8b-120ff9a888f2: Single-cell RNA-seq reveals the cell-type-specific molecular and genetic associations to lupus (https://cellxgene.cziscience.com/collections/436154da-bcf1-4130-9c8b-120ff9a888f2)
- ddfad306-714d-4cc0-9985-d9072820c530: Single-cell multi-omics analysis of the immune response in COVID-19 (https://cellxgene.cziscience.com/collections/ddfad306-714d-4cc0-9985-d9072820c530)
- 0a839c4b-10d0-4d64-9272-684c49a2c8ba: COVID-19 immune features revealed by a large-scale single-cell transcriptome atlas (https://cellxgene.cziscience.com/collections/0a839c4b-10d0-4d64-9272-684c49a2c8ba)
- 4f889ffc-d4bc-4748-905b-8eb9db47a2ed: Immunophenotyping of COVID-19 and influenza highlights the role of type I interferons in development of severe COVID-19 (https://cellxgene.cziscience.com/collections/4f889ffc-d4bc-4748-905b-8eb9db47a2ed)
res.head()
| collection_id | collection_url | name | description | llm_reason | |
|---|---|---|---|---|---|
| 0 | dde06e0f-ab3b-46be-96a2-a8082383c4a1 | https://cellxgene.cziscience.com/collections/d... | Single-cell eQTL mapping identifies cell type ... | The human immune system displays remarkable va... | Large-scale peripheral blood / PBMC resource (... |
| 1 | ced320a1-29f3-47c1-a735-513c7084d508 | https://cellxgene.cziscience.com/collections/c... | Asian Immune Diversity Atlas (AIDA) | The relationships of human diversity with biom... | Asian Immune Diversity Atlas: multi-donor circ... |
| 2 | e9360edf-b0b7-4e01-bce8-e596814f13e7 | https://cellxgene.cziscience.com/collections/e... | Multi-omic profiling reveals age-related immun... | The generation and maintenance of immunity is ... | Multi-omic profiling of peripheral immunity in... |
| 3 | 4a9fd4d7-d870-4265-89a5-ad51ab811d89 | https://cellxgene.cziscience.com/collections/4... | ScaleBio Single Cell RNA Sequencing of Human P... | In an effort to increase throughput and reduce... | ScaleBio Single Cell RNA Sequencing of Human P... |
| 4 | 436154da-bcf1-4130-9c8b-120ff9a888f2 | https://cellxgene.cziscience.com/collections/4... | Single-cell RNA-seq reveals the cell-type-spec... | Systemic lupus erythematosus (SLE) is a hetero... | Large PBMC cohort (systemic lupus study) with ... |
自动化注释#
我们已将所有自动注释算法统一到omicverse.single.Annotation类中。
ov.datasets.download_data_requests( url='https://datasets.cellxgene.cziscience.com/89c999bd-2ba9-4281-9d22-4261347c5c78.h5ad', file_path='pbmc_ref_cellxgene_test1.h5ad', dir='./data')
🔍 Downloading data to ./data/pbmc_ref_cellxgene_test1.h5ad...
✅ Download completed
'./data/pbmc_ref_cellxgene_test1.h5ad'
adata_ref=ov.read( 'data/pbmc_ref_cellxgene_test1.h5ad')adata_ref
AnnData object with n_obs × n_vars = 44721 × 24505
obs: 'nCount_RNA', 'nFeature_RNA', 'percent.mt', 'percent.rps', 'percent.rpl', 'percent.rrna', 'nCount_SCT', 'nFeature_SCT', 'seurat_clusters', 'singler', 'cell.type.fine', 'cell.type.coarse', 'IFN1', 'HLA1', 'donor_id', 'DPS', 'DTF', 'Admission', 'Ventilated', 'tissue_ontology_term_id', 'assay_ontology_term_id', 'disease_ontology_term_id', 'cell_type_ontology_term_id', 'development_stage_ontology_term_id', 'self_reported_ethnicity_ontology_term_id', 'sex_ontology_term_id', 'is_primary_data', 'suspension_type', 'tissue_type', 'cell_type', 'assay', 'disease', 'sex', 'tissue', 'self_reported_ethnicity', 'development_stage', 'observation_joinid'
var: 'feature_is_filtered', 'feature_name', 'feature_reference', 'feature_biotype', 'feature_length', 'feature_type'
uns: 'citation', 'organism', 'organism_ontology_term_id', 'schema_reference', 'schema_version', 'title'
obsm: 'X_pca', 'X_umap'
print(adata_ref.X.max(),adata_ref.X.max()<ov.np.log1p(1e4))
7.449498 True
Seurat标签转移#
首先,我们演示了Seurat标签转移方法,该方法已被广泛使用。
X_counts_recovered, size_factors_sub=ov.pp.recover_counts(adata_ref.X, 1e4, 1e5, log_base=None, chunk_size=10000)adata_ref.layers['counts']=X_counts_recoveredadata_ref.X=adata_ref.layers['counts'].copy()
print(adata_ref.X.max(),adata_ref.X.max()<ov.np.log1p(1e4))
1718 False
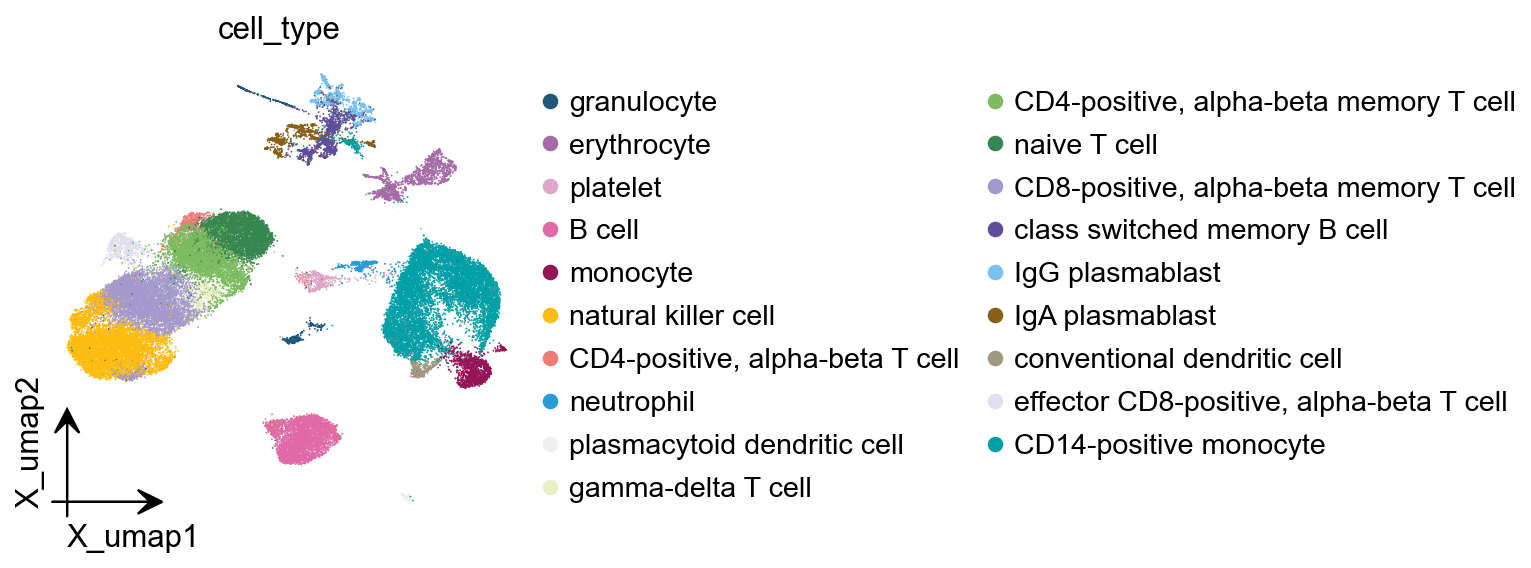
ov.pl.embedding( adata_ref, basis='X_umap', color='cell_type')
adata_ref.var.head()
| feature_is_filtered | feature_name | feature_reference | feature_biotype | feature_length | feature_type | |
|---|---|---|---|---|---|---|
| ENSG00000235399 | False | ENSG00000235399 | NCBITaxon:9606 | gene | 524 | lncRNA |
| ENSG00000151338 | False | MIPOL1 | NCBITaxon:9606 | gene | 2191 | protein_coding |
| ENSG00000182173 | False | TSEN54 | NCBITaxon:9606 | gene | 2036 | protein_coding |
| ENSG00000148297 | False | MED22 | NCBITaxon:9606 | gene | 933 | protein_coding |
| ENSG00000269997 | False | ENSG00000269997 | NCBITaxon:9606 | gene | 553 | lncRNA |
adata_ref.var.index=adata_ref.var['feature_name'].tolist()
加权KNN标签转移#
加权KNN算法是另一种广泛使用的标签转移方法。
scANVI注释#
scANVI是一种基于深度学习的标签转移方法。
adata.var_names_make_unique()adata_ref.var_names_make_unique()adata.obs_names_make_unique()adata_ref.obs_names_make_unique()
objref=ov.single.AnnotationRef( adata_query=adata, adata_ref=adata_ref, celltype_key='cell_type')
Concatenated adata saved to self.adata_new
objref.preprocess( mode='shiftlog|pearson', n_HVGs=3000, batch_key='integrate_batch')
🔍 [2025-11-03 15:13:41] Running preprocessing in 'cpu' mode...
Begin robust gene identification
After filtration, 16801/16801 genes are kept.
Among 16801 genes, 14976 genes are robust.
✅ Robust gene identification completed successfully.
Begin size normalization: shiftlog and HVGs selection pearson
🔍 Count Normalization:
Target sum: 500000.0
Exclude highly expressed: True
Max fraction threshold: 0.2
⚠️ Excluding 5 highly-expressed genes from normalization computation
Excluded genes: ['HBA2', 'DEFA1B', 'HBG1', 'HBB', 'MALAT1']
✅ Count Normalization Completed Successfully!
✓ Processed: 47,421 cells × 14,976 genes
✓ Runtime: 3.70s
🔍 Highly Variable Genes Selection (Experimental):
Method: pearson_residuals
Target genes: 3,000
Batch key: integrate_batch
Theta (overdispersion): 100
✅ Experimental HVG Selection Completed Successfully!
✓ Selected: 3,000 highly variable genes out of 14,976 total (20.0%)
✓ Results added to AnnData object:
• 'highly_variable': Boolean vector (adata.var)
• 'highly_variable_rank': Float vector (adata.var)
• 'highly_variable_nbatches': Int vector (adata.var)
• 'highly_variable_intersection': Boolean vector (adata.var)
• 'means': Float vector (adata.var)
• 'variances': Float vector (adata.var)
• 'residual_variances': Float vector (adata.var)
Time to analyze data in cpu: 9.15 seconds.
✅ Preprocessing completed successfully.
Added:
'highly_variable_features', boolean vector (adata.var)
'means', float vector (adata.var)
'variances', float vector (adata.var)
'residual_variances', float vector (adata.var)
'counts', raw counts layer (adata.layers)
End of size normalization: shiftlog and HVGs selection pearson
computing PCA🔍
with n_comps=50
🖥️ Using sklearn PCA for CPU computation
🖥️ sklearn PCA backend: CPU computation
finished✅ (0:00:31)
CellTypist注释#
CellTypist是一种预训练的细胞类型分类器。
objref.train( method='harmony', n_pcs=50)
...Begin using harmony to correct batch effect
Using CUDA device: NVIDIA H100 80GB HBM3
✅ TorchDR available for GPU-accelerated PCA
Omicverse mode: cpu
Detected device: cuda
🖥️ Using PyTorch CPU acceleration for Harmony
🔍 [2025-11-03 15:14:42] Running Harmony integration...
Max iterations: 10
Convergence threshold: 0.0001
✅ Harmony converged after 6 iterations
Harmony integrated embeddings saved to self.adata_query.obsm['X_pca_harmony'] and self.adata_ref.obsm['X_pca_harmony']
AnnData object with n_obs × n_vars = 2700 × 16801
var: 'gene_ids'
obsm: 'X_pca_harmony_anno'
ad_pre=objref.predict( method='harmony', n_neighbors=15,)
Weighted KNN with n_neighbors = 15 ... finished!
harmony_prediction saved to adata.obs['harmony_prediction']
harmony_uncertainty saved to adata.obs['harmony_uncertainty']
ov.pp.mde( ad_pre,use_rep='X_pca_harmony_anno')
🔍 MDE Dimensionality Reduction:
Mode: cpu
Embedding dimensions: 2
Neighbors: 15
Repulsive fraction: 0.7
Using representation: X_pca_harmony_anno
Principal components: 50
Using CUDA device: NVIDIA H100 80GB HBM3
✅ TorchDR available for GPU-accelerated PCA
🔍 Computing k-nearest neighbors graph...
🔍 Creating MDE embedding...
🔍 Optimizing embedding...
✅ MDE Dimensionality Reduction Completed Successfully!
✓ Embedding shape: 2,700 cells × 2 dimensions
✓ Runtime: 2.32s
✓ Results added to AnnData object:
• 'X_mde': MDE coordinates (adata.obsm)
• 'neighbors': Neighbors metadata (adata.uns)
• 'distances': Distance matrix (adata.obsp)
• 'connectivities': Connectivity matrix (adata.obsp)
ov.pl.embedding( ad_pre, basis='X_mde', color='harmony_prediction')

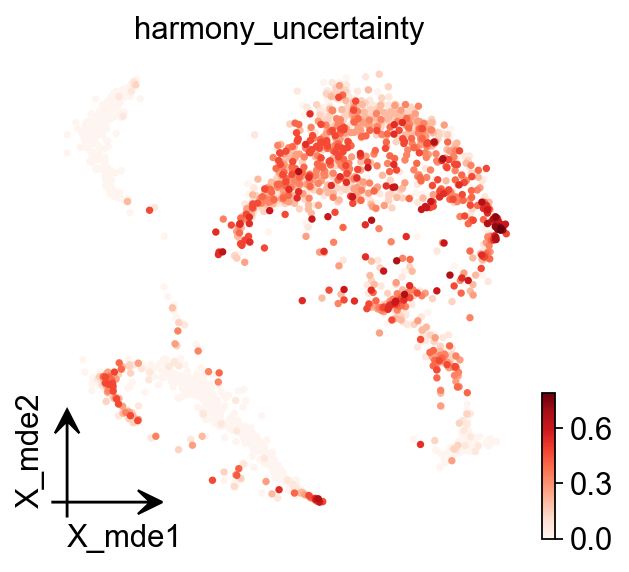
ad_pre.obs['harmony_uncertainty']=ad_pre.obs['harmony_uncertainty'].astype(float)
ov.pl.embedding( ad_pre, basis='X_mde', color='harmony_uncertainty', cmap='Reds')
PopV共识注释#
在OmicVerse中,我们集成了多种算法的共识注释方法。
objref.train( method='scVI', n_layers=2, n_latent=30, gene_likelihood="nb")
...Begin using scVI to correct batch effect
INFO:lightning.pytorch.utilities.rank_zero:GPU available: True (cuda), used: True
INFO:lightning.pytorch.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:lightning.pytorch.utilities.rank_zero:HPU available: False, using: 0 HPUs
INFO:lightning.pytorch.utilities.rank_zero:You are using a CUDA device ('NVIDIA H100 80GB HBM3') that has Tensor Cores. To properly utilize them, you should set `torch.set_float32_matmul_precision('medium' | 'high')` which will trade-off precision for performance. For more details, read https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html#torch.set_float32_matmul_precision
INFO:lightning.pytorch.accelerators.cuda:LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
INFO:lightning.pytorch.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=169` reached.
scVI integrated embeddings saved to self.adata_query.obsm['X_scVI'] and self.adata_ref.obsm['X_scVI']
AnnData object with n_obs × n_vars = 2700 × 16801
obs: 'harmony_prediction', 'harmony_uncertainty'
var: 'gene_ids'
uns: 'neighbors', 'REFERENCE_MANU', 'harmony_prediction_colors_rgba', 'harmony_prediction_colors'
obsm: 'X_pca_harmony_anno', 'X_mde', 'X_scVI_anno'
obsp: 'distances', 'connectivities'
ad_pre1=objref.predict( method='scVI', n_neighbors=15,)
Weighted KNN with n_neighbors = 15 ... finished!
scVI_prediction saved to adata.obs['scVI_prediction']
scVI_uncertainty saved to adata.obs['scVI_uncertainty']
ov.pl.embedding( ad_pre1, basis='X_mde', color='scVI_prediction')

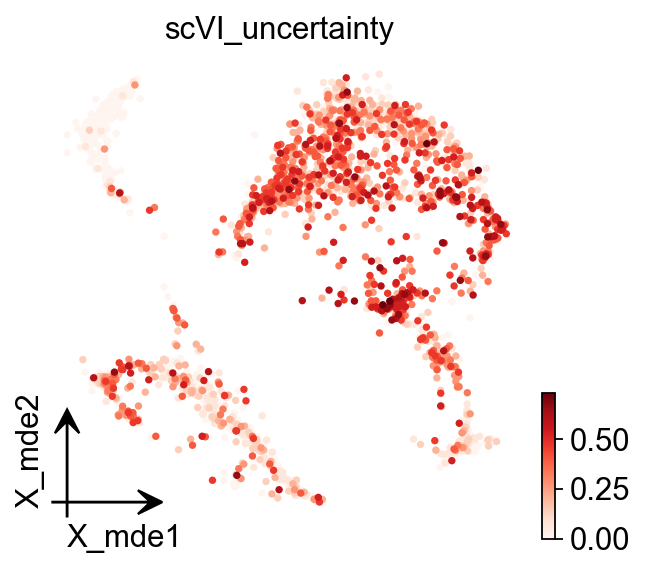
ad_pre1.obs['scVI_uncertainty']=ad_pre1.obs['scVI_uncertainty'].astype(float)
ov.pl.embedding( ad_pre1, basis='X_mde', color='scVI_uncertainty', cmap='Reds')
ad_pre.write('result/knn_anno1.h5ad')