无参考自动化单细胞细胞类型注释#
截至2025年,用于自动细胞类型注释的算法已大幅增加。Omicverse致力于减少不同算法之间的差异,因此我们将自动注释方法分为两类:带有单细胞参考和没有单细胞参考。每个类别都有其自身的优缺点。在本教程中,我们仅介绍使用方法,不会比较不同的算法。
本章重点关注无单细胞参考方法,意味着可以在不下载现有单细胞数据集的情况下执行细胞类型注释。
# 导入库
import scanpy as sc
import omicverse as ov
ov.plot_set(font_path='Arial')
# 启用自动重新加载以进行开发
%load_ext autoreload
%autoreload 2
🔬 Starting plot initialization...
Using already downloaded Arial font from: /tmp/omicverse_arial.ttf
Registered as: Arial
🧬 Detecting GPU devices…
✅ NVIDIA CUDA GPUs detected: 1
• [CUDA 0] NVIDIA H100 80GB HBM3
Memory: 79.1 GB | Compute: 9.0
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
🔖 Version: 1.7.8rc2 📚 Tutorials: https://omicverse.readthedocs.io/
✅ plot_set complete.
数据预处理#
加载数据集#
为了快速演示我们在无参考细胞类型注释方面的能力,我们使用经典的pbmc3k数据集。您可以使用omicverse.datasets.pbmc3k直接导入它,或通过以下链接下载:https://falexwolf.de/data/pbmc3k_raw.h5ad。
adata=ov.datasets.pbmc3k()adata
Loading PBMC 3k dataset (raw)
🔍 Downloading data to ./data/pbmc3k_raw.h5ad
✅ Download completed
Loading data from ./data/pbmc3k_raw.h5ad
✅ Successfully loaded: 2700 cells × 32738 genes
AnnData object with n_obs × n_vars = 2700 × 32738
var: 'gene_ids'
懒惰预处理#
由于单个数据集缺乏批次效应,我们直接应用了omicverse的默认处理工作流进行预处理。
# 质量控制
adata=ov.pp.qc(adata, tresh={'mito_perc': 0.05, 'nUMIs': 500, 'detected_genes': 250})
# 归一化和高变基因(HVGs)计算
adata=ov.pp.preprocess(adata,mode='shiftlog|pearson',n_HVGs=2000,target_sum=1e4)
# 保存整个基因并过滤非HVGs
adata.raw = adata
adata = adata[:, adata.var.highly_variable_features]
# 缩放adata.X
ov.pp.scale(adata)
# 降维
ov.pp.pca(adata,layer='scaled',n_pcs=50)
# 邻域图构建
ov.pp.neighbors(adata, n_neighbors=15, n_pcs=50, use_rep='scaled|original|X_pca')
# 聚类
ov.pp.leiden(adata)
# 可视化降维(X_mde=X_umap+GPU)
ov.pp.umap(adata)
adata
🖥️ Using CPU mode for QC...
📊 Step 1: Calculating QC Metrics
✓ Gene Family Detection:
┌──────────────────────────────┬────────────────────┬────────────────────┐
│ Gene Family │ Genes Found │ Detection Method │
├──────────────────────────────┼────────────────────┼────────────────────┤
│ Mitochondrial │ 13 │ Auto (MT-) │
├──────────────────────────────┼────────────────────┼────────────────────┤
│ Ribosomal │ 106 │ Auto (RPS/RPL) │
├──────────────────────────────┼────────────────────┼────────────────────┤
│ Hemoglobin │ 13 │ Auto (regex) │
└──────────────────────────────┴────────────────────┴────────────────────┘
✓ QC Metrics Summary:
┌─────────────────────────┬────────────────────┬─────────────────────────┐
│ Metric │ Mean │ Range (Min - Max) │
├─────────────────────────┼────────────────────┼─────────────────────────┤
│ nUMIs │ 2367 │ 548 - 15844 │
├─────────────────────────┼────────────────────┼─────────────────────────┤
│ Detected Genes │ 847 │ 212 - 3422 │
├─────────────────────────┼────────────────────┼─────────────────────────┤
│ Mitochondrial % │ 2.2% │ 0.0% - 22.6% │
├─────────────────────────┼────────────────────┼─────────────────────────┤
│ Ribosomal % │ 34.9% │ 1.1% - 59.4% │
├─────────────────────────┼────────────────────┼─────────────────────────┤
│ Hemoglobin % │ 0.0% │ 0.0% - 1.4% │
└─────────────────────────┴────────────────────┴─────────────────────────┘
📈 Original cell count: 2,700
🔧 Step 2: Quality Filtering (SEURAT)
Thresholds: mito≤0.05, nUMIs≥500, genes≥250
📊 Seurat Filter Results:
• nUMIs filter (≥500): 0 cells failed (0.0%)
• Genes filter (≥250): 3 cells failed (0.1%)
• Mitochondrial filter (≤0.05): 57 cells failed (2.1%)
✓ Filters applied successfully
✓ Combined QC filters: 60 cells removed (2.2%)
🎯 Step 3: Final Filtering
Parameters: min_genes=200, min_cells=3
Ratios: max_genes_ratio=1, max_cells_ratio=1
filtered out 19041 genes that are detected in less than 3 cells
✓ Final filtering: 0 cells, 19,041 genes removed
🔍 Step 4: Doublet Detection
⚠️ Note: 'scrublet' detection is too old and may not work properly
💡 Consider using 'doublets_method=sccomposite' for better results
🔍 Running scrublet doublet detection...
🔍 Running Scrublet Doublet Detection:
Mode: cpu
Computing doublet prediction using Scrublet algorithm
🔍 Filtering genes and cells...
🔍 Normalizing data and selecting highly variable genes...
🔍 Count Normalization:
Target sum: median
Exclude highly expressed: False
✅ Count Normalization Completed Successfully!
✓ Processed: 2,640 cells × 13,697 genes
✓ Runtime: 0.00s
🔍 Highly Variable Genes Selection:
Method: seurat
⚠️ Gene indices [7846] fell into a single bin: normalized dispersion set to 1
💡 Consider decreasing `n_bins` to avoid this effect
✅ HVG Selection Completed Successfully!
✓ Selected: 1,738 highly variable genes out of 13,697 total (12.7%)
✓ Results added to AnnData object:
• 'highly_variable': Boolean vector (adata.var)
• 'means': Float vector (adata.var)
• 'dispersions': Float vector (adata.var)
• 'dispersions_norm': Float vector (adata.var)
🔍 Simulating synthetic doublets...
🔍 Normalizing observed and simulated data...
🔍 Count Normalization:
Target sum: 1000000.0
Exclude highly expressed: False
✅ Count Normalization Completed Successfully!
✓ Processed: 2,640 cells × 1,738 genes
✓ Runtime: 0.00s
🔍 Count Normalization:
Target sum: 1000000.0
Exclude highly expressed: False
✅ Count Normalization Completed Successfully!
✓ Processed: 5,280 cells × 1,738 genes
✓ Runtime: 0.01s
🔍 Embedding transcriptomes using PCA...
🔍 Calculating doublet scores...
using data matrix X directly
🔍 Calling doublets with threshold detection...
📊 Automatic threshold: 0.239
📈 Detected doublet rate: 1.6%
🔍 Detectable doublet fraction: 39.5%
📊 Overall doublet rate comparison:
• Expected: 5.0%
• Estimated: 4.0%
✅ Scrublet Analysis Completed Successfully!
✓ Results added to AnnData object:
• 'doublet_score': Doublet scores (adata.obs)
• 'predicted_doublet': Boolean predictions (adata.obs)
• 'scrublet': Parameters and metadata (adata.uns)
✓ Scrublet completed: 42 doublets removed (1.6%)
🔍 [2025-11-03 14:00:25] Running preprocessing in 'cpu' mode...
Begin robust gene identification
After filtration, 13697/13697 genes are kept.
Among 13697 genes, 13697 genes are robust.
✅ Robust gene identification completed successfully.
Begin size normalization: shiftlog and HVGs selection pearson
🔍 Count Normalization:
Target sum: 10000.0
Exclude highly expressed: True
Max fraction threshold: 0.2
⚠️ Excluding 0 highly-expressed genes from normalization computation
Excluded genes: []
✅ Count Normalization Completed Successfully!
✓ Processed: 2,598 cells × 13,697 genes
✓ Runtime: 0.11s
🔍 Highly Variable Genes Selection (Experimental):
Method: pearson_residuals
Target genes: 2,000
Theta (overdispersion): 100
✅ Experimental HVG Selection Completed Successfully!
✓ Selected: 2,000 highly variable genes out of 13,697 total (14.6%)
✓ Results added to AnnData object:
• 'highly_variable': Boolean vector (adata.var)
• 'highly_variable_rank': Float vector (adata.var)
• 'highly_variable_nbatches': Int vector (adata.var)
• 'highly_variable_intersection': Boolean vector (adata.var)
• 'means': Float vector (adata.var)
• 'variances': Float vector (adata.var)
• 'residual_variances': Float vector (adata.var)
Time to analyze data in cpu: 1.18 seconds.
✅ Preprocessing completed successfully.
Added:
'highly_variable_features', boolean vector (adata.var)
'means', float vector (adata.var)
'variances', float vector (adata.var)
'residual_variances', float vector (adata.var)
'counts', raw counts layer (adata.layers)
End of size normalization: shiftlog and HVGs selection pearson
computing PCA🔍
with n_comps=50
🖥️ Using sklearn PCA for CPU computation
🖥️ sklearn PCA backend: CPU computation
finished✅ (0:00:00)
🖥️ Using Scanpy CPU to calculate neighbors...
🔍 K-Nearest Neighbors Graph Construction:
Mode: cpu
Neighbors: 15
Method: umap
Metric: euclidean
Representation: scaled|original|X_pca
PCs used: 50
computing neighbors
🔍 Computing neighbor distances...
🔍 Computing connectivity matrix...
💡 Using UMAP-style connectivity
✓ Graph is fully connected
✅ KNN Graph Construction Completed Successfully!
✓ Processed: 2,598 cells with 15 neighbors each
✓ Results added to AnnData object:
• 'neighbors': Neighbors metadata (adata.uns)
• 'distances': Distance matrix (adata.obsp)
• 'connectivities': Connectivity matrix (adata.obsp)
finished: added to `.uns['neighbors']`
`.obsp['distances']`, distances for each pair of neighbors
`.obsp['connectivities']`, weighted adjacency matrix (0:00:02)
running Leiden clustering
finished: found 9 clusters and added
'leiden', the cluster labels (adata.obs, categorical) (0:00:00)
🔍 [2025-11-03 14:00:30] Running UMAP in 'cpu' mode...
🖥️ Using Scanpy CPU UMAP...
🔍 UMAP Dimensionality Reduction:
Mode: cpu
Method: umap
Components: 2
Min distance: 0.5
{'n_neighbors': 15, 'method': 'umap', 'random_state': 0, 'metric': 'euclidean', 'use_rep': 'scaled|original|X_pca', 'n_pcs': 50}
🔍 Computing UMAP parameters...
🔍 Computing UMAP embedding (classic method)...
✅ UMAP Dimensionality Reduction Completed Successfully!
✓ Embedding shape: 2,598 cells × 2 dimensions
✓ Results added to AnnData object:
• 'X_umap': UMAP coordinates (adata.obsm)
• 'umap': UMAP parameters (adata.uns)
✅ UMAP completed successfully.
AnnData object with n_obs × n_vars = 2598 × 2000
obs: 'nUMIs', 'mito_perc', 'ribo_perc', 'hb_perc', 'detected_genes', 'cell_complexity', 'passing_mt', 'passing_nUMIs', 'passing_ngenes', 'n_genes', 'doublet_score', 'predicted_doublet', 'leiden'
var: 'gene_ids', 'mt', 'ribo', 'hb', 'n_cells', 'percent_cells', 'robust', 'means', 'variances', 'residual_variances', 'highly_variable_rank', 'highly_variable_features'
uns: 'scrublet', 'status', 'status_args', 'REFERENCE_MANU', 'log1p', 'hvg', 'pca', 'scaled|original|pca_var_ratios', 'scaled|original|cum_sum_eigenvalues', 'neighbors', 'leiden', 'umap'
obsm: 'X_pca', 'scaled|original|X_pca', 'X_umap'
varm: 'PCs', 'scaled|original|pca_loadings'
layers: 'counts', 'scaled'
obsp: 'distances', 'connectivities'
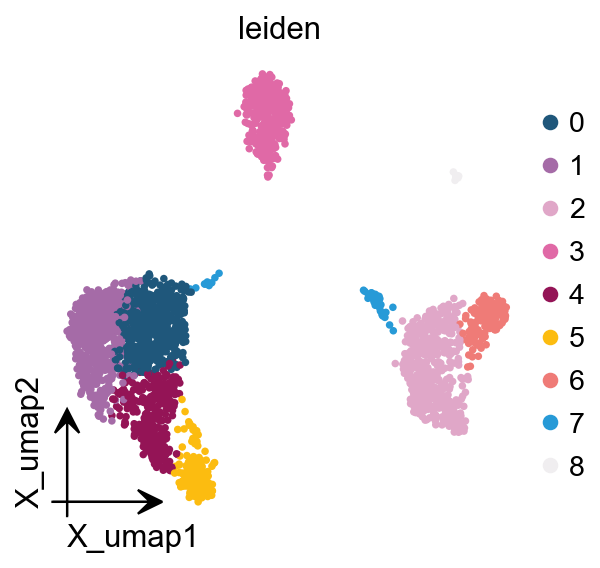
ov.pl.umap( adata, color='leiden')
自动化注释#
我们已将所有自动注释算法统一到omicverse.single.Annotation类中。
obj=ov.single.Annotation(adata)
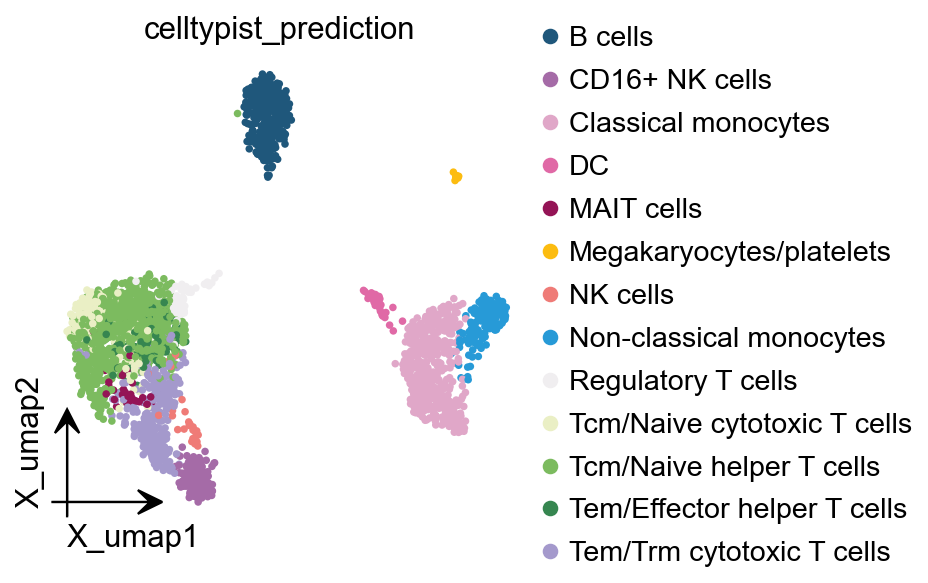
Celltypist自动注释#
在这里,我们介绍第一个算法Celltypist,它发表在Cell和Science杂志上,我们已将其集成到Omicverse的自动注释模块中。重要的是,为了获得最优的预训练模型,我们已纳入Agent来进行查询处理。
res=obj.query_reference( source='celltypist', data_desc='pbmc of human', llm_model='gpt-5-mini', llm_api_key='sk-*', llm_provider='openai', llm_base_url='https://api.openai.com/v1',)res.head()
CellTypist model table saved to self.celltypist_models_df
✓ LLM-selected CellTypist models:
- Immune_All_Low.pkl: Immune_All_Low.pkl
- Immune_All_High.pkl: Immune_All_High.pkl
- Healthy_COVID19_PBMC.pkl: Healthy_COVID19_PBMC.pkl
- Adult_COVID19_PBMC.pkl: Adult_COVID19_PBMC.pkl
- PaediatricAdult_COVID19_PBMC.pkl: PaediatricAdult_COVID19_PBMC.pkl
| model | description | version | No_celltypes | source | date | default | llm_reason | |
|---|---|---|---|---|---|---|---|---|
| 0 | Immune_All_Low.pkl | immune sub-populations combined from 20 tissue... | v2 | 98 | https://doi.org/10.1126/science.abl5197 | 2022-07-16 00:20:42.927778 | True | High-resolution immune reference (98 immune su... |
| 1 | Immune_All_High.pkl | immune populations combined from 20 tissues of... | v2 | 32 | https://doi.org/10.1126/science.abl5197 | 2022-07-16 08:53:00.959521 | NaN | Compact immune reference (32 broad immune popu... |
| 2 | Healthy_COVID19_PBMC.pkl | peripheral blood mononuclear cell types from h... | v1 | 51 | https://doi.org/10.1038/s41591-021-01329-2 | 2022-03-10 05:08:08.224597 | NaN | PBMC-specific reference derived from healthy a... |
| 3 | Adult_COVID19_PBMC.pkl | peripheral blood mononuclear cell types from C... | v1 | 20 | https://doi.org/10.1038/s41591-020-0944-y | 2024-06-24 19:37:48.634397 | NaN | PBMC reference from adult human donors (COVID-... |
| 4 | PaediatricAdult_COVID19_PBMC.pkl | peripheral blood mononuclear cell types of pae... | v1 | 42 | https://doi.org/10.1038/s41586-021-04345-x | 2025-10-15 00:51:41.857714 | NaN | PBMC reference spanning pediatric and adult hu... |
基于LLM的建议,我们发现Immune_All_Low.pkl是最适合我们数据的模型。然后我们使用download_reference_pkl函数下载此模型。
!pwd
/scratch/users/steorra/analysis/omic_test
# 下载模型
obj.download_reference_pkl(
'Immune_All_Low.pkl',
save_path="/scratch/users/steorra/analysis/omic_test/models/Immune_All_Low.pkl",
# force_download=True)
🔍 Downloading data to /scratch/users/steorra/analysis/omic_test/models/Immune_All_Low.pkl
✅ Download completed
https://celltypist.cog.sanger.ac.uk/models/Pan_Immune_CellTypist/v2/Immune_All_Low.pkl
✓ Model saved to /scratch/users/steorra/analysis/omic_test/models/Immune_All_Low.pkl
'/scratch/users/steorra/analysis/omic_test/models/Immune_All_Low.pkl'
下载模型后,我们需要将其加载到我们的注释类中。
obj.add_reference_pkl('/scratch/users/steorra/analysis/omic_test/models/Immune_All_Low.pkl')
obj.model.cell_types[:5]
array(['Age-associated B cells', 'Alveolar macrophages', 'B cells',
'CD16+ NK cells', 'CD16- NK cells'], dtype=object)
obj.annotate( method='celltypist')
WARNING:celltypist.logger:⚠️ Warning: invalid expression matrix, expect ALL genes and log1p normalized expression to 10000 counts per cell. The prediction result may not be accurate
running Leiden clustering
finished: found 55 clusters and added
'over_clustering', the cluster labels (adata.obs, categorical) (0:00:00)
Celltypist prediction saved to adata.obs['celltypist_prediction']
Celltypist decision matrix saved to adata.obsm['celltypist_decision_matrix']
Celltypist probability matrix saved to adata.obsm['celltypist_probability_matrix']
ov.pl.embedding( obj.adata, basis='X_umap', color='celltypist_prediction')
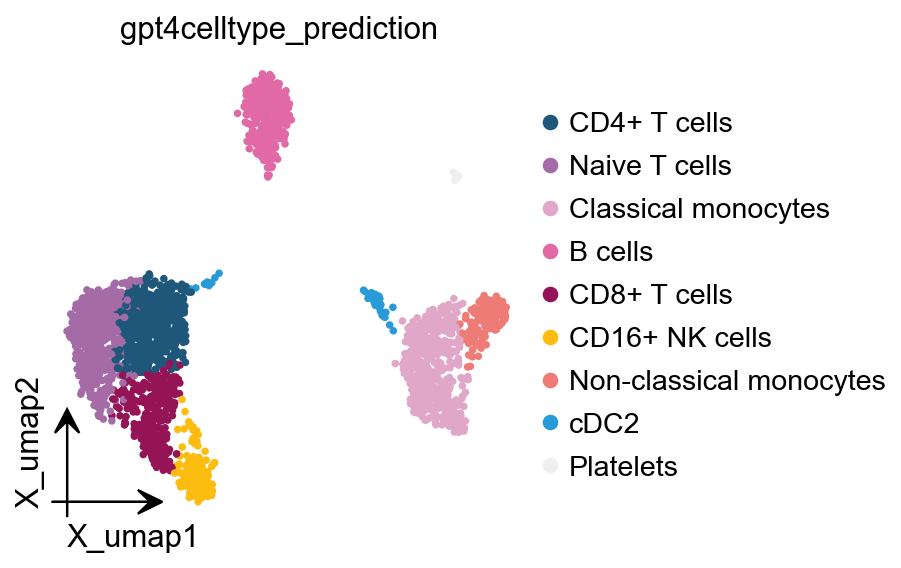
gpt4celltype自动注释#
此外,我们还提供gpt4celltype来自动注释细胞类型。
# 导入os库
import os
os.environ['AGI_API_KEY'] = 'sk-*' # 用您的实际API密钥替换
obj=ov.single.Annotation(adata)
result = obj.annotate(
method='gpt4celltype',
tissuename='PBMC',
speciename='human',
model='gpt-5-mini',
provider='openai',
topgenenumber=5
)
...get cell type marker
ranking genes
finished: added to `.uns['rank_genes_groups']`
'names', sorted np.recarray to be indexed by group ids
'scores', sorted np.recarray to be indexed by group ids
'logfoldchanges', sorted np.recarray to be indexed by group ids
'pvals', sorted np.recarray to be indexed by group ids
'pvals_adj', sorted np.recarray to be indexed by group ids (0:00:00)
Note: AGI API key found: returning the cell type annotations.
Note: It is always recommended to check the results returned by GPT-4 in case of AI hallucination, before going to downstream analysis.
GPT4celltype prediction saved to adata.obs['gpt4celltype_prediction']
ov.pl.embedding( obj.adata, basis='X_umap', color='gpt4celltype_prediction')
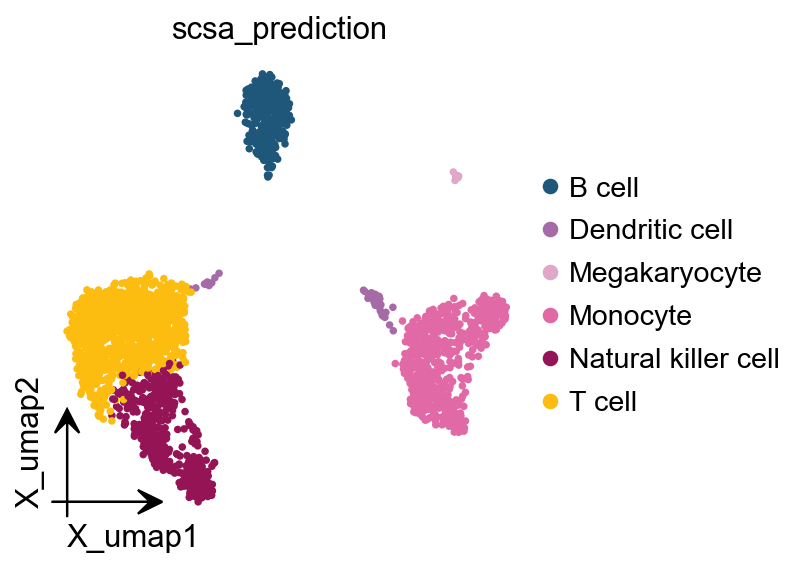
SCSA自动注释#
我们在https://omicverse.readthedocs.io/en/latest/Tutorials-single/t_cellanno/中有详细的SCSA教程。在这里,我们仅提供了一个简单的教程来演示注释类的能力。
obj=ov.single.Annotation(adata)
为了执行SCSA自动注释,我们需要首先下载数据库。
obj.download_scsa_db( 'temp/pySCSA_2024_v1_plus.db')
🔍 Downloading data to temp/pySCSA_2024_v1_plus.db
✅ Download completed
SCSA database saved to temp/pySCSA_2024_v1_plus.db
'temp/pySCSA_2024_v1_plus.db'
obj.add_reference_scsa_db( 'temp/pySCSA_2024_v1_plus.db')
obj.annotate( method='scsa', cluster_key='leiden', foldchange=1.5, pvalue=0.01, celltype='normal', target='cellmarker', tissue='All', )
ranking genes
finished (0:00:00)
...Auto annotate cell
🔍 Version V2.2 [2024/12/18]
📊 DB load: GO_items:47347, Human_GO:3, Mouse_GO:3,
CellMarkers:82887, CancerSEA:1574, PanglaoDB:24223
Ensembl_HGNC:61541, Ensembl_Mouse:55414
<omicverse.single._SCSA.Annotator object at 0x7f65c53f6bc0>
🔍 Version V2.2 [2024/12/18]
📊 DB load: GO_items:47347, Human_GO:3, Mouse_GO:3,
CellMarkers:82887, CancerSEA:1574, PanglaoDB:24223
Ensembl_HGNC:61541, Ensembl_Mouse:55414
📦 Load markers: 70276
============================================================
🔬 Analyzing 9 clusters...
============================================================
[1/9] Cluster 0 │ 48 genes │ 988 other genes
[2/9] Cluster 1 │ 29 genes │ 1006 other genes
[3/9] Cluster 2 │ 346 genes │ 930 other genes
[4/9] Cluster 3 │ 118 genes │ 946 other genes
[5/9] Cluster 4 │ 51 genes │ 1011 other genes
[6/9] Cluster 5 │ 160 genes │ 934 other genes
[7/9] Cluster 6 │ 429 genes │ 865 other genes
[8/9] Cluster 7 │ 274 genes │ 890 other genes
[9/9] Cluster 8 │ 144 genes │ 944 other genes
============================================================
✅ Cluster analysis completed! (9/9 processed)
============================================================
================================================================================
📋 Cell Type Annotation Results
================================================================================
Cluster Type Cell Type Score Times
--------------------------------------------------------------------------------
0 ⚠️ ? T cell|CD4+ T cell 9.945870198596303|5.360011326945353 1.86
1 ⚠️ ? T cell|Naive CD8+ T cell 5.451241689383974|4.768292656196209 1.14
2 ⚠️ ? Monocyte|Macrophage 14.354365574078278|8.528970464022539 1.68
3 ✅ Good B cell 13.78474042389334 4.02
4 ⚠️ ? Natural killer cell|T cell 8.221301039648155|6.61215702423662 1.24
5 ✅ Good Natural killer cell 15.26958201763484 3.82
6 ⚠️ ? Monocyte|Macrophage 10.86288578272659|8.672538874890472 1.25
7 ⚠️ ? Dendritic cell|Monocyte 9.461295981098543|5.912723904106833 1.60
8 ✅ Good Megakaryocyte 10.05563188309469 2.01
================================================================================
...cell type added to scsa_prediction on obs of anndata
ov.pl.embedding( obj.adata, basis='X_umap', color='scsa_prediction')