TCGA数据库预处理#
我们经常从TCGA数据库下载患者生存数据进行分析,以验证基因在癌症中的重要性。然而,TCGA数据库的预处理往往令人头疼。这里,我们在ov中引入了TCGA模块,提供了一种快速处理从TCGA数据库下载的文件格式的方法。我们需要准备3个文件作为输入:
gdc_sample_sheet(
.tsv):TCGA的Sample Sheet按钮,从中可以获取tsv文件gdc_download_files(
folder):TCGA的Download/Cart按钮,获取包含所有所选文件的tar.gzclinical_cart(
folder):TCGA的Clinical按钮,可获取包含所有临床信息的tar.gz
import omicverse as ov
import scanpy as sc
ov.plot_set()
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
Version: 1.6.4, Tutorials: https://omicverse.readthedocs.io/
All dependencies are satisfied.
读取TCGA计数#
这里,我们使用ov.bulk.TCGA处理之前下载的gdc_sample_sheet、gdc_download_files和clinical_cart。原始计数、fpkm和tpm矩阵将存储在anndata对象中。
%%time
gdc_sample_sheep='data/TCGA_OV/gdc_sample_sheet.2024-07-05.tsv'
gdc_download_files='data/TCGA_OV/gdc_download_20240705_180129.081531'
clinical_cart='data/TCGA_OV/clinical.cart.2024-07-05'
aml_tcga=ov.bulk.pyTCGA(gdc_sample_sheep,gdc_download_files,clinical_cart)
aml_tcga.adata_init()
tcga module init success
...index init
... expression matrix init
...anndata construct
CPU times: user 1min 30s, sys: 4.16 s, total: 1min 34s
Wall time: 1min 34s
我们可以保存anndata对象以供下次使用。
aml_tcga.adata.write_h5ad('data/TCGA_OV/ov_tcga_raw.h5ad',compression='gzip')
注意:每次读取anndata文件时,我们都需要使用三个路径初始化TCGA对象,以便后续的TCGA功能(如生存分析)能够正常使用。
如果您希望创建自己的TCGA数据,我们在此提供了示例数据供下载:
TCGA OV: https://figshare.com/ndownloader/files/47461946
gdc_sample_sheep='data/TCGA_OV/gdc_sample_sheet.2024-07-05.tsv'
gdc_download_files='data/TCGA_OV/gdc_download_20240705_180129.081531'
clinical_cart='data/TCGA_OV/clinical.cart.2024-07-05'
aml_tcga=ov.bulk.pyTCGA(gdc_sample_sheep,gdc_download_files,clinical_cart)
aml_tcga.adata_read('data/TCGA_OV/ov_tcga_raw.h5ad')
tcga module init success
... anndata reading
Meta初始化#
由于TCGA读取的是gene_id,我们需要将其转换为gene_name并添加患者的基本信息。因此,我们需要初始化患者的meta信息。
aml_tcga.adata_meta_init()
...anndata meta init ['gene_name', 'gene_type'] ['Case ID', 'Sample Type']
AnnData object with n_obs × n_vars = 429 × 60664
obs: 'Case ID', 'Sample Type'
var: 'gene_name', 'gene_type', 'gene_id'
layers: 'deseq_normalize', 'fpkm', 'tpm'
生存分析初始化#
我们之前设置了Clinical的路径,但实际上在之前的过程中我们没有导入患者信息,只是初步确定了患者的TCGA id,因此我们需要初始化临床信息。
aml_tcga.survial_init()
aml_tcga.adata
AnnData object with n_obs × n_vars = 429 × 60664
obs: 'Case ID', 'Sample Type', 'vital_status', 'days'
var: 'gene_name', 'gene_type', 'gene_id'
layers: 'deseq_normalize', 'fpkm', 'tpm'
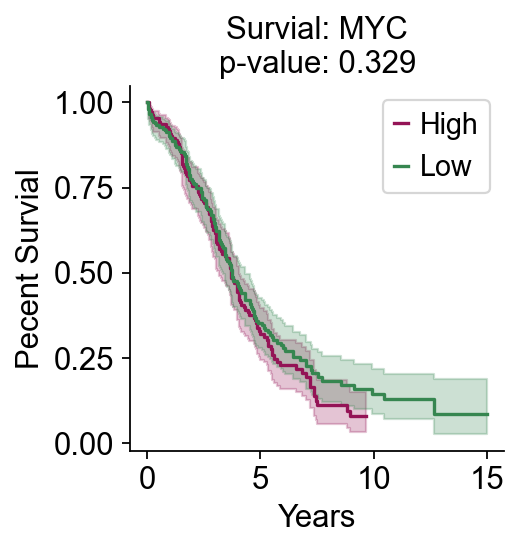
要可视化您感兴趣的基因,我们可以使用survival_analysis来完成。
aml_tcga.survival_analysis('MYC',layer='deseq_normalize',plot=True)
(0.9528907736380975, 0.328984565709021)
如果您想计算所有基因的生存分析,也可以使用survial_analysis_all来完成。这可能需要较长时间。
aml_tcga.survial_analysis_all()
aml_tcga.adata
不要忘记保存您的结果。
aml_tcga.adata.write_h5ad('data/TCGA_OV/ov_tcga_survial_all.h5ad',compression='gzip')