STPath — zero-shot generative foundation model#
STPath (Huang et al., npj Digital Medicine 2025) is a
generative foundation model trained on 1,170 paired ST + H&E
slides covering 17 organs and 38,984 genes. The published
weights (HuggingFace tlhuang/STPath)
take only GigaPath features and tile centroids as input — no
reference Visium slide is required, no per-slide
fine-tuning. On HEST-Bench it leads the next best method by
+6.9 % Pearson.
This makes STPath the right pick when you have an H&E-only slide of a tissue covered by its training mixture (any of the 17 organs × Visium / Visium-HD / Xenium / CosMx) and want spot-level expression without doing any per-slide training. For organs / panels outside its vocabulary use HEST-FM (with a paired reference) or STFlow (per-slide fine-tune).
HuggingFace access — prov-gigapath/prov-gigapath (used
to extract the 1536-d patch features STPath expects) is gated.
Request access at https://huggingface.co/prov-gigapath/prov-gigapath,
wait for the Microsoft Research approval email, then
huggingface-cli login with a token that includes that
agreement. Without it the embed cell raises GatedRepoError.
Environment#
import warnings
warnings.filterwarnings('ignore')
import omicverse as ov
import lazyslide as zs
ov.utils.ov_plot_set()
print('omicverse', ov.__version__, '| lazyslide', zs.__version__)
🔬 Starting plot initialization...
🧬 Detecting GPU devices…
✅ NVIDIA CUDA GPUs detected: 1
• [CUDA 0] NVIDIA H100 80GB HBM3
Memory: 79.1 GB | Compute: 9.0
____ _ _ __
/ __ \____ ___ (_)___| | / /__ _____________
/ / / / __ `__ \/ / ___/ | / / _ \/ ___/ ___/ _ \
/ /_/ / / / / / / / /__ | |/ / __/ / (__ ) __/
\____/_/ /_/ /_/_/\___/ |___/\___/_/ /____/\___/
🔖 Version: 2.2.1rc1 📚 Tutorials: https://omicverse.readthedocs.io/
✅ plot_set complete.
omicverse 2.2.1rc1 | lazyslide 0.9.2
How the WSI flows through LazySlide#
ov.space.histo wraps LazySlide
for everything WSI-related. The mapping is:
omicverse call |
LazySlide / wsidata under the hood |
|---|---|
|
|
|
|
|
|
|
omicverse-specific: writes the STPath prediction as |
Drop down to zs.pp.* / zs.tl.* / zs.pl.* whenever you
need finer control than these convenience wrappers offer.
Inputs STPath expects#
STPath needs only a tiled WSI; no Visium reference. Concretely:
wsi—wsidata.WSIDatawrapping the H&E.GigaPath tile features in
wsi.tables['gigapath_tiles']— produced byov.space.histo.embed(wsi, model='gigapath'). GigaPath outputs are 1536-dimensional, matching the dimensionality STPath was trained on; substituting other backbones is not supported.organ token (e.g.
'Breast','Kidney','Lung','Colon','Liver', …, one of STPath’s 17 organs). Passing the wrong organ degrades quality; passingNonefalls back to a generic'Others'token.technology token (
'Visium','Visium-HD','Xenium','CosMx', …). Defaults to'Visium'.
For a real H&E-only slide:
wsi = ov.space.histo.open_wsi('/path/to/slide.tif')
ov.space.histo.tile(wsi, tile_px=224, mpp=0.5)
ov.space.histo.embed(wsi, model='gigapath', batch_size=16)
The demo below uses the breast Visium slide for direct head-to-head comparison with the other HE-zoo tutorials; the Visium counts are not used by STPath, only the H&E.
Model weights & cache layout#
STPath needs two pretrained checkpoints + one git clone + the gene vocabulary. Everything below downloads on first use; nothing needs manual setup beyond requesting GigaPath access on HuggingFace.
What |
From |
To |
Size |
Gated? |
|---|---|---|---|---|
GigaPath patch encoder ( |
|
~4 GB |
yes — request access |
|
STPath model weights ( |
|
~1 GB |
no |
|
STPath python package |
git clone |
|
~100 MB |
no |
Gene vocabulary ( |
shipped inside the STPath clone |
|
small |
no |
tile features (per slide / tile-grid) |
computed once |
|
~10–50 MB |
— |
$OV_HISTO_CACHE defaults to ~/.cache/omicverse/histo;
override with OV_HISTO_CACHE=/some/path (recommended on
HPC: point it at scratch). $HF_HOME defaults to
~/.cache/huggingface; override with HF_HOME=/some/path.
Requesting GigaPath access: visit the model card, click “Request access”, fill the Microsoft Research data- use agreement, wait for approval (usually hours to a few days). After approval, on this machine:
huggingface-cli login # paste a Read token
The embed(model='gigapath') call below will then succeed.
Without access it raises GatedRepoError.
Load the demo dataset#
adata, wsi = ov.space.histo.load_breast()
adata
AnnData object with n_obs × n_vars = 3798 × 36601
obs: 'in_tissue', 'array_row', 'array_col'
var: 'gene_ids', 'feature_types', 'genome'
uns: 'spatial', 'histo'
obsm: 'spatial'
wsi

Reader: tiffslide
Dimensions: 24240×24240 (h×w), 1 Pyramid
Pixel physical size: 0.31 MPP
SpatialData object
└── Images
└── 'wsi_thumbnail': DataArray[cyx] (3, 2000, 2000)
with coordinate systems:
▸ 'global', with elements:
wsi_thumbnail (Images)
Tile the WSI on a 224 px @ 0.5 µm/pixel grid (LazySlide’s find_tissues + tile_tissues under the hood).
ov.space.histo.tile(wsi, tile_px=224, mpp=0.5)
print('tiles:', len(wsi.shapes['tiles']))
tiles: 1426
Extract GigaPath features (1536-d, gated)#
GigaPath is a 1.1 B-parameter pathology FM (Microsoft Research
Providence Health). LazySlide’s
feature_extractionhandles the gated download and HF auth for us. On first run it downloads ~4 GB of weights into$HF_HOME/hub; subsequent runs use the cache. The resulting features are stored aswsi.tables['gigapath_tiles'](AnnData with one row per tile and 1536 feature columns) and are also cached to$OV_HISTO_CACHE/tile_features/so notebook re-runs skip the embed entirely.
ov.space.histo.embed(wsi, model='gigapath',
batch_size=16, num_workers=0)
wsi.tables['gigapath_tiles']
AnnData object with n_obs × n_vars = 1426 × 1536
obs: 'tile_id', 'library_id'
uns: 'spatialdata_attrs'
Zero-shot prediction#
predict_expression(method='stpath', …) does the following
under the hood:
on first use, auto-clones the upstream STPath repo into
$OV_HISTO_CACHE/STPath/and adds it tosys.path,downloads the model weights (
tlhuang/STPath/stfm.pth) via HuggingFace Hub,instantiates
STPathInference(gene vocabulary + organ / tech tokenizers + the spatial-transformer denoiser),feeds
(gigapath features, tile centroids, organ id, tech id)through the model in a single forward pass,wraps the result in an
AnnDataand stores it aswsi.tables['stpath_tiles'].
Key parameters#
organ='Breast'— STPath’s organ-conditioning token. Pick one of the 17 organs the model was trained on (Breast,Kidney,Lung,Colon,Liver, …). Wrong organ ⇒ degraded quality.tech='Visium'— sequencing platform token; defaults to'Visium'. Other choices include'Visium-HD','Xenium','CosMx'.genes=['EPCAM', 'ERBB2', …]— gene panel to keep. PassingNonereturns all 38,984 genes from STPath’s vocabulary (pred.Xbecomes a 1426 × 38,984 dense matrix, ~150 MB — fine on disk but heavier in memory).fm_backbone='gigapath'— must staygigapath; the published weights were trained on 1536-d GigaPath features specifically.feature_key=None— override only if you stored GigaPath features under a non-default key.cache_dir— override the default$OV_HISTO_CACHE(where the STPath repo + weights cache).weight_path— explicit local path tostfm.pth(STPath checkpoint). When given, the HuggingFace download oftlhuang/STPathis skipped.fm_weight_path— explicit local path to the GigaPathpytorch_model.bin. When given, the HuggingFace download ofprov-gigapath/prov-gigapathis skipped (useful when the host doesn’t have network access to HuggingFace or when GigaPath has been pre-staged elsewhere).hf_token— explicit HuggingFace token (otherwise reads$HUGGING_FACE_HUB_TOKENthen~/.cache/huggingface/token).
Air-gapped run (skip both HuggingFace downloads)#
pred = ov.space.histo.predict_expression(
wsi, method='stpath',
organ='Breast', tech='Visium',
genes=['EPCAM', 'ERBB2'],
fm_weight_path='/scratch/weights/gigapath/pytorch_model.bin',
weight_path='/scratch/weights/stpath/stfm.pth',
cache_dir='/scratch/omicverse_histo',
)
pred = ov.space.histo.predict_expression(
wsi,
method='stpath',
organ='Breast',
tech='Visium',
genes=['EPCAM', 'ERBB2', 'CD68', 'ACTA2', 'VIM'],
)
pred
n_genes: 38984, n_tech: 5, n_species: 6, n_organs: 25, n_cancer_annos: 5, n_domain_annos: 10
Model loaded from /scratch/users/steorra/cache/omicverse_histo/hf/models--tlhuang--STPath/snapshots/3346881771f2ddb5575532df3df1b5477846d10a/stfm.pth
Starting inference...
Return results...
AnnData object with n_obs × n_vars = 1426 × 5
obs: 'tile_id', 'library_id'
uns: 'histo'
obsm: 'spatial'
Reading the output#
pred is an AnnData with:
pred.X(n_tiles × n_genes) — log1p predicted expression (float32)pred.var_names— the requested gene symbolspred.obsm['spatial'](n_tiles × 2) — tile pixel centroidspred.uns['histo']— run metadata (method,fm_backbone,organ,tech)
print('shape :', pred.shape)
print('var_names :', list(pred.var_names))
print('coords range:', pred.obsm['spatial'].min(0), '→',
pred.obsm['spatial'].max(0))
print('metadata :', pred.uns['histo'])
shape : (1426, 5)
var_names : ['EPCAM', 'ERBB2', 'CD68', 'ACTA2', 'VIM']
coords range: [4468.5 4355.5] → [22223.5 23521.5]
metadata : {'method': 'stpath', 'fm_backbone': 'gigapath', 'organ': 'Breast', 'tech': 'Visium'}
Visualise predictions on the tissue#
ov.pl.embedding(pred, basis='spatial',
color=['EPCAM', 'ERBB2', 'CD68', 'ACTA2'],
cmap='magma', s=12, ncols=2, frameon=False)
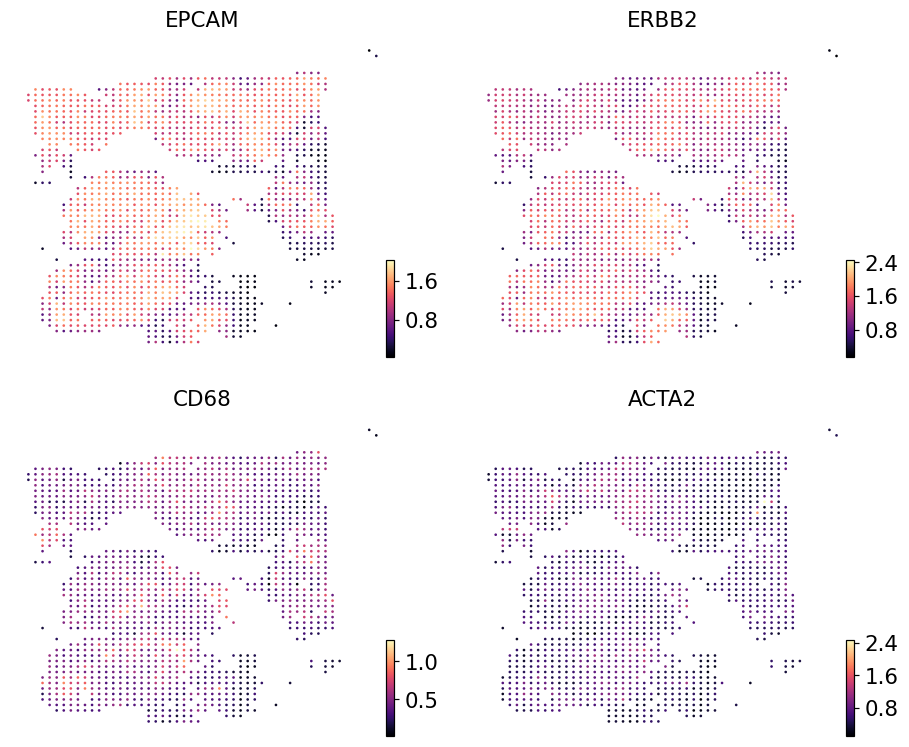
Real Visium counts for the same genes#
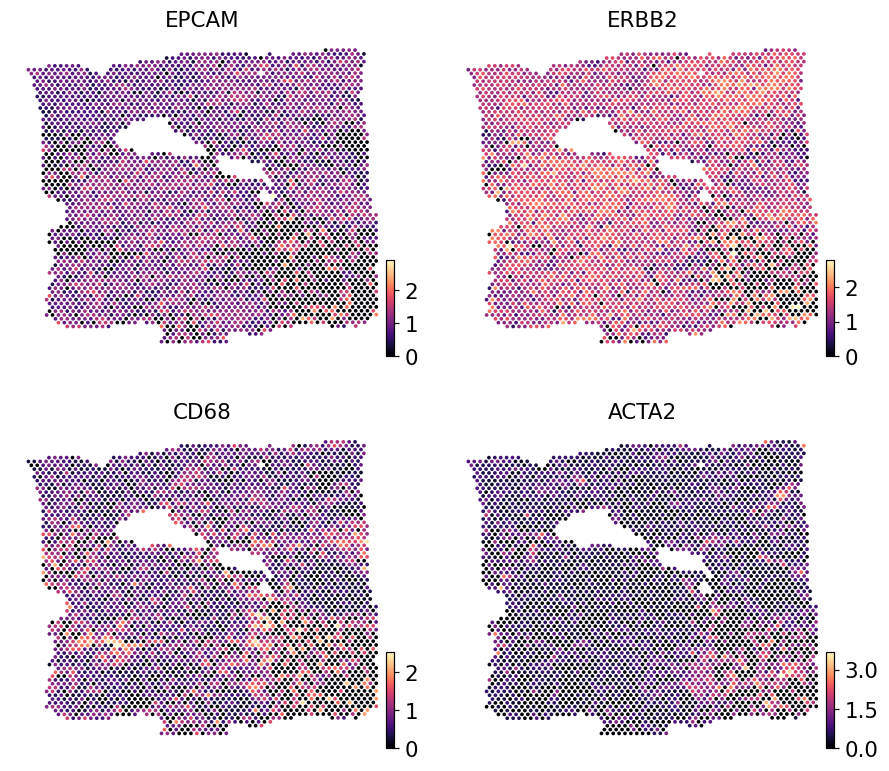
STPath was not trained on this slide — it predicts zero-shot from the H&E. Plotting the real Visium expression for the same genes gives a qualitative read on how close the zero-shot output is to ground truth.
ref = adata.copy()
ov.pp.normalize_total(ref, target_sum=1e4)
ov.pp.log1p(ref)
ov.pl.embedding(ref, basis='spatial',
color=['EPCAM', 'ERBB2', 'CD68', 'ACTA2'],
cmap='magma', s=24, ncols=2, frameon=False)
🔍 Count Normalization:
Target sum: 10000.0
Exclude highly expressed: False
✅ Count Normalization Completed Successfully!
✓ Processed: 3,798 cells × 36,601 genes
✓ Runtime: 0.14s
Per-gene scatter on Section 1 (zero-shot quality)#
STPath has never seen this slide during training, so this scatter already shows held-out generalisation quality. Match each Visium spot to its nearest predicted tile, scatter real log1p expression against the prediction, Pearson r in the title.
import numpy as np, matplotlib.pyplot as plt
from scipy.spatial import cKDTree
from scipy.stats import pearsonr
spot_xy = adata.obsm['spatial']
tile_xy = pred.obsm['spatial']
nn = cKDTree(tile_xy).query(spot_xy, k=1)[1]
ref_X = adata[:, pred.var_names].X
ref_X = np.log1p(ref_X.toarray() if hasattr(ref_X, 'toarray') else ref_X)
pred_X = pred.X[nn]
fig, axes = plt.subplots(1, len(pred.var_names),
figsize=(3 * len(pred.var_names), 3))
for ax, g, i in zip(axes, pred.var_names, range(len(pred.var_names))):
ax.scatter(ref_X[:, i], pred_X[:, i], s=4, alpha=0.4)
r, _ = pearsonr(ref_X[:, i], pred_X[:, i])
lo = float(min(ref_X[:, i].min(), pred_X[:, i].min()))
hi = float(max(ref_X[:, i].max(), pred_X[:, i].max()))
ax.plot([lo, hi], [lo, hi], 'k--', lw=0.8, alpha=0.5)
ax.set_title(f'{g}: r={r:.2f}')
ax.set_xlabel('Section 1 real log1p')
ax.set_ylabel('STPath prediction')
plt.tight_layout()

Zero-shot prediction on a never-seen slide (Section 2)#
STPath was trained on 1,170 paired slides covering 17 organs — but this slide (and every other Section 1 we use in HE-zoo) was not in that training set. To additionally check generalisation to a brand-new H&E, predict on the adjacent Section 2 of the same patient block (separate Visium dataset from 10x).
load_breast(section=2) downloads it on first use
(~1.7 GB cached) and returns the same (adata, wsi)
shape.
adata_s2, wsi_s2 = ov.space.histo.load_breast(section=2)
ov.space.histo.tile(wsi_s2, tile_px=224, mpp=0.5)
ov.space.histo.embed(wsi_s2, model='gigapath',
batch_size=16, num_workers=0)
pred_s2 = ov.space.histo.predict_expression(
wsi_s2,
method='stpath',
organ='Breast', tech='Visium',
genes=['EPCAM', 'ERBB2', 'CD68', 'ACTA2', 'VIM'],
)
pred_s2
n_genes: 38984, n_tech: 5, n_species: 6, n_organs: 25, n_cancer_annos: 5, n_domain_annos: 10
Model loaded from /scratch/users/steorra/cache/omicverse_histo/hf/models--tlhuang--STPath/snapshots/3346881771f2ddb5575532df3df1b5477846d10a/stfm.pth
Starting inference...
Return results...
AnnData object with n_obs × n_vars = 1857 × 5
obs: 'tile_id', 'library_id'
uns: 'histo'
obsm: 'spatial'
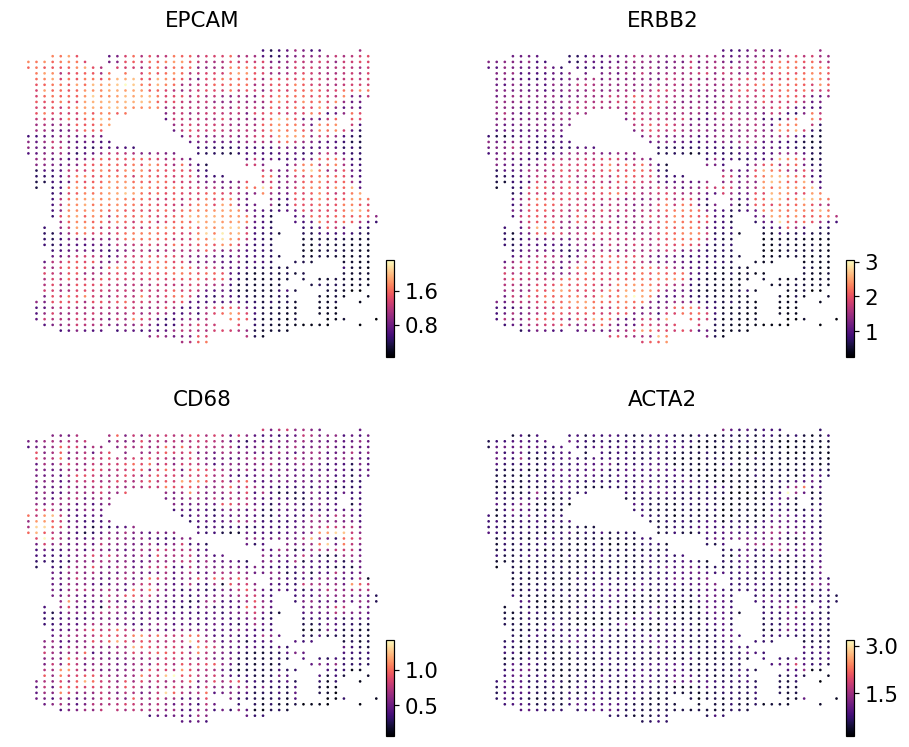
Spatial visualisation on Section 2 — prediction#
Same plotter as Section 1, just pointed at the held-out slide’s predicted AnnData.
ov.pl.embedding(pred_s2, basis='spatial',
color=['EPCAM', 'ERBB2', 'CD68', 'ACTA2'],
cmap='magma', s=12, ncols=2, frameon=False)
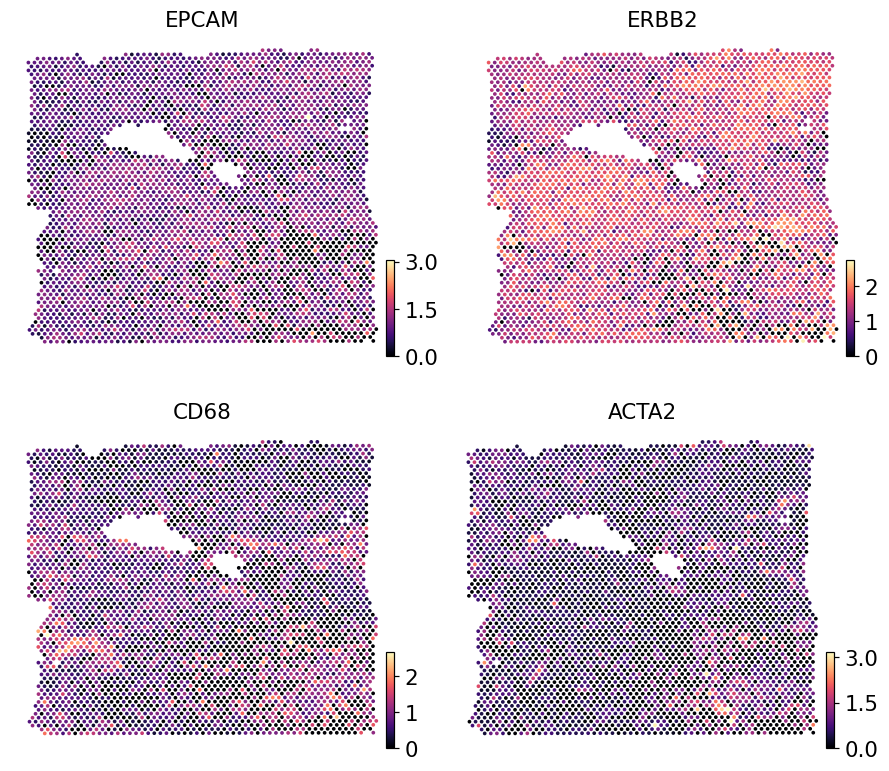
Spatial visualisation on Section 2 — real Visium counts#
Section 2’s real Visium expression for the same panel, log1p-normalised to match the predictor’s output scale.
ref_s2 = adata_s2.copy()
ov.pp.normalize_total(ref_s2, target_sum=1e4)
ov.pp.log1p(ref_s2)
ov.pl.embedding(ref_s2, basis='spatial',
color=['EPCAM', 'ERBB2', 'CD68', 'ACTA2'],
cmap='magma', s=24, ncols=2, frameon=False)
🔍 Count Normalization:
Target sum: 10000.0
Exclude highly expressed: False
✅ Count Normalization Completed Successfully!
✓ Processed: 3,987 cells × 36,601 genes
✓ Runtime: 0.03s
Per-gene scatter on Section 2 (truly zero-shot)#
Match each Section 2 Visium spot to its nearest Section 2 predicted tile and scatter real log1p expression against the prediction. Pearson r in the title.
import numpy as np, matplotlib.pyplot as plt
from scipy.spatial import cKDTree
from scipy.stats import pearsonr
spot_xy = adata_s2.obsm['spatial']
tile_xy = pred_s2.obsm['spatial']
nn = cKDTree(tile_xy).query(spot_xy, k=1)[1]
ref_X = adata_s2[:, pred_s2.var_names].X
ref_X = np.log1p(ref_X.toarray() if hasattr(ref_X, 'toarray') else ref_X)
pred_X = pred_s2.X[nn]
fig, axes = plt.subplots(1, len(pred_s2.var_names),
figsize=(3 * len(pred_s2.var_names), 3))
for ax, g, i in zip(axes, pred_s2.var_names, range(len(pred_s2.var_names))):
ax.scatter(ref_X[:, i], pred_X[:, i], s=4, alpha=0.4)
r, _ = pearsonr(ref_X[:, i], pred_X[:, i])
lo = float(min(ref_X[:, i].min(), pred_X[:, i].min()))
hi = float(max(ref_X[:, i].max(), pred_X[:, i].max()))
ax.plot([lo, hi], [lo, hi], 'k--', lw=0.8, alpha=0.5)
ax.set_title(f'{g}: r={r:.2f}')
ax.set_xlabel('Section 2 real log1p')
ax.set_ylabel('STPath prediction')
plt.tight_layout()

Where to go next#
STPath’s output is interchangeable with a real Visium table.
Feed it straight to ov.space.pySTAGATE, ov.space.svg, or
any other spatial analysis. For pixel-level / sub-spot
resolution on the same H&E, switch to
iStar (requires the matched Visium
counts as a reference). For benchmarking against a Ridge
baseline on the same panel, see
HEST-FM.